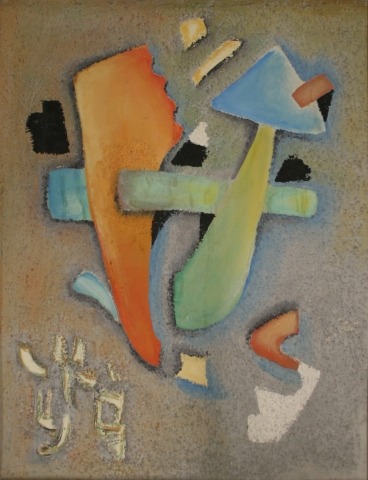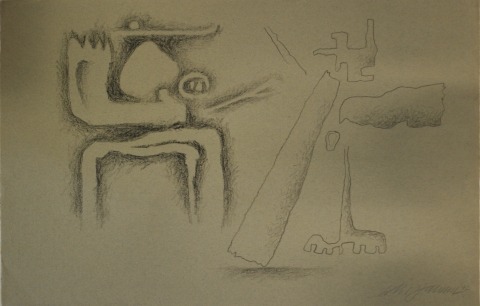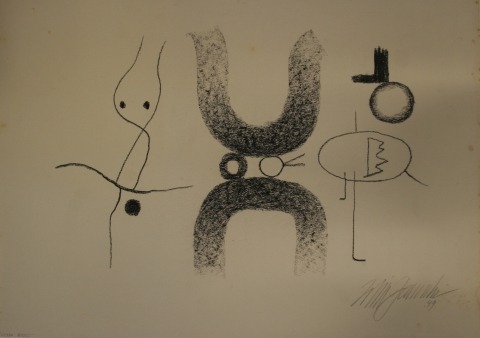Over the years, various works have been submitted to the Archiv Baumeister that to date have not been registered in any catalog raisonné in order to clarify their authorship. Among these are not only works by the artist but also paintings, drawings, and gouaches that cannot be ascribed to him. Some are works that have adopted his formal language or are even signed with his name, that is, genuine forgeries. Others have been submitted that lead us to believe that someone painted their own Baumeister, which therefore should be classified as a copy. Moreover, yet other works have emerged that are clearly signed with the name Baumeister, but whose formal language is a completely different one, so that they cannot be classified as a forgery or copy, but might derive from another artist with the same name.
There are currently seventy works known to the Archiv in circulation. This page will be regularly updated with newly received works.
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")